

Feedback Loops in RAG have redefined how AI systems reason with live data. By combining language models with real-time document retrieval, it bridges the gap between static training data and evolving knowledge sources. Yet as enterprises scale RAG into production, they quickly face latency, compute waste, and inconsistent accuracy.
According to LangChain’s documentation, a standard RAG pipeline performs multiple heavy operations—embedding generation, vector search, retrieval, and inference for every query. Now imagine thousands of users asking similar questions every day. The result? Bloated costs, sluggish responses, and redundant processing.
This is where caching and feedback loops revolutionize the game. Together, they transform RAG from an expensive demo into a self-improving, production-grade intelligence layer.
Understanding RAG’s Core Performance Bottlenecks
RAG’s architecture excels in flexibility but suffers when scaled. Each stage in the retrieval-generation cycle contributes to latency and inflated resource use.
| Bottleneck | Description | Impact |
|---|---|---|
| Latency Stack-Up | Query → Embedding → Search → Retrieval → LLM response. | Adds 3–10 s lag per request. |
| Redundant Work | Re-embedding or re-retrieving repeated questions. | 40–70 % wasted computation. |
| Cost Multiplication | Each inference burns tokens + GPU cycles. | 10–20× infra cost escalation. |
| Static Learning | System never learns from feedback signals. | Quality stagnates; hallucinations persist. |
For enterprises building customer support bots or internal assistants, these inefficiencies directly impact ROI. The key is turning every query into a learning opportunity rather than a fresh expense.
Feedback Loops in RAG Systems
A feedback loop lets RAG learn from its past—improving both retrieval accuracy and response quality through user signals and automated evaluation.
At its core, RAG combines:
-
a Retriever (vector DBs like FAISS, Pinecone, ChromaDB) that fetches context, and
-
a Generator (LLM) that crafts the answer.
By adding feedback loops, each interaction strengthens this pair.
Types of Feedback
-
Explicit Feedback (User-Driven)
Users rate, correct, or flag AI answers (“👍/👎,” “Not helpful”). This data refines ranking weights or retrains embedding models.Example: A user corrects a leave-policy answer; the system logs it, updates retriever scores, and improves future accuracy.
-
Implicit Feedback (Behavior-Driven)
Behavioral cues time spent, clicks, or re-queries indicate satisfaction or confusion.Example: High bounce rate signals irrelevant retrievals; system auto-adjusts document weights.
-
Automated Feedback (Self-Evaluation)
Using reinforcement learning or secondary models, RAG self-checks response faithfulness, confidence, or factual grounding.Example: Comparing multiple generated outputs and storing the most coherent one (self-consistency scoring).
Integrating these feedback streams allows the retriever to rank documents more effectively and the generator to adjust prompts dynamically an approach discussed in our related post on RAG Architecture to Reduce AI Hallucinations.
Temporal Categories of Feedback Loops
| Feedback Type | Learning Interval | Example | Impact |
|---|---|---|---|
| Short-Term (Online) | Real-time ranking updates. | Adjust retrieval weight after each thumbs-down. | Immediate improvement. |
| Long-Term (Batch) | Periodic model retraining. | Weekly fine-tuning of embedding model. | Sustained accuracy. |
| Hybrid | Combines both. | Live correction + monthly retrain. | Balances speed and stability. |
This layered feedback cycle parallels the philosophy shared in our article on Advanced RAG Techniques, which explores hybrid adaptation for large-scale enterprise data.
The Caching Revolution: Eliminating Redundant Work
Caching is the invisible engine behind every scalable AI product. As highlighted by AWS researchers in their LLM Cache whitepaper, storing frequent results avoids costly recomputation and accelerates performance exponentially.
Caching Layers that Matter
| Caching Layer | Function | Benefit |
|---|---|---|
| Embedding Cache | Saves vector representations for repeated inputs. | Skips re-embedding; 40 % faster retrieval. |
| Retrieval Cache | Stores top-K document results. | Bypasses vector search calls. |
| Response Cache | Caches complete LLM answers for identical or semantically similar queries. | Instant replies (< 100 ms). |
A caching layer integrated within enterprise-grade Generative AI Development Services can reduce compute cost by 60–90 %, enhance user experience, and minimize environmental footprint since every avoided API call saves both time and energy.

Real-World Impact: The Data Doesn’t Lie
A SaaS platform serving 50 k+ monthly queries implemented dual-layer caching (retrieval + response) and feedback analytics.
The outcome:
| Metric | Before Optimization | After Caching + Feedback | Improvement |
|---|---|---|---|
| Avg Response Time | 4 s | 0.8 s | 80 % faster |
| LLM API Cost | 100 % baseline | 15 % of original | 85 % saving |
| Cache Hit Rate | – | 70 % | High reuse efficiency |
| Customer Satisfaction | 3.2/5 | 4.6/5 | +44 % improvement |
| Support Escalations | Frequent | Reduced 40 % | Operational relief |
These aren’t edge cases they’re repeatable results when caching and feedback loops co-exist.
Understanding the Cost Equation
| Layer | Approx. Cost Without Cache | Approx. Cost With Cache | Savings % |
|---|---|---|---|
| LLM Inference | $0.04 / query | $0.008 / query | 80 % |
| Vector Search Ops | $0.01 / query | $0.003 / query | 70 % |
| Total Monthly Infra (50 k queries) | ~ $2,500 | ~ $600 | 76 % |
| Developer Maintenance Time | 40 h / month | 12 h / month | 70 % efficiency |
Key takeaway: Caching + feedback loops deliver linear cost savings while compounding quality improvement.
Architectural View: Caching Meets Learning
This diagram shows a lightweight but powerful feedback-cache hybrid that underpins modern Retrieval-Augmented Feedback Systems (RAFS).
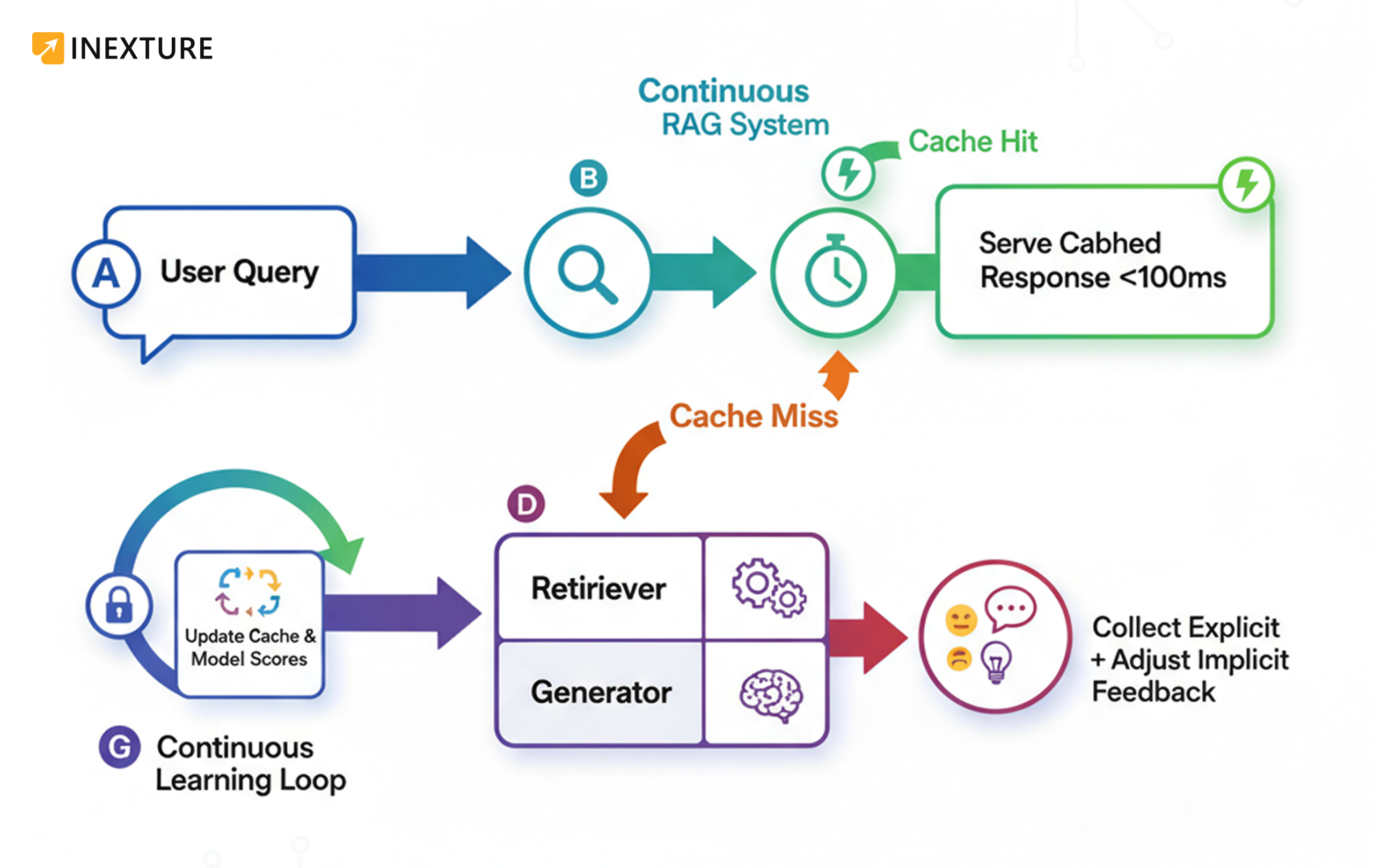
Industry Use-Cases and Trends
1. Customer Support Automation
Companies like Guesty and Freshworks use retrieval-augmented feedback to refine chatbots dynamically—achieving 30 % higher engagement and 25 % faster response times.
2. Healthcare Diagnostics
RAG + feedback models trained with medical datasets have reached 89 % factual accuracy and cut diagnosis time by 20 %.
3. Finance and Compliance
Banks deploy hybrid caching to store regulatory Q&A results, reducing duplicate token use while maintaining audit trails for compliance.
These trends align with Gartner’s 2024 Generative AI Hype Cycle, which lists RAG optimization among top investment priorities for enterprise AI.
Best Practices for Implementing Caching + Feedback
- Use semantic cache keys to capture meaning, not just raw input.
- Auto-invalidate outdated entries when model or data sources update.
- Blend human-in-the-loop evaluation for sensitive use cases.
- Track key metrics—cache hit ratio, latency, hallucination rate, cost per query.
- Adopt hybrid loops: instant corrections + scheduled retraining.
By applying these, developers move from reactive debugging to proactive optimization.
The Future: From Reactive to Self-Evolving RAG
Caching tackles redundancy; feedback drives evolution. Together they create RAG systems that think faster, learn continuously, and spend less.
The next evolution lies in Eval Loops real-time monitoring systems measuring accuracy, hallucination, latency, and cost. Combining Eval Loops with caching and feedback forms a closed learning circuit—an architecture resilient enough for millions of daily queries.
This holistic infrastructure mindset is what separates prototypes from products.
Conclusion
The future of RAG isn’t just about smarter retrieval it’s about sustainable intelligence. Caching reduces waste; feedback loops refine precision; evaluation cycles ensure trust.
Organizations embracing these optimizations today are building the blueprint for tomorrow’s enterprise-ready AI. If you’re planning to productionize your GenAI workflows, partner with the leading AI Development Agency and Company to design adaptive, high-performance systems tailored to your domain.
FAQs
Q1: How do feedback loops improve RAG accuracy?
They capture user interactions and retrain retrieval rankings or prompts, continuously improving factual accuracy and reducing hallucinations.
Q2: What’s the cost advantage of caching in RAG?
Caching can cut LLM API and vector DB costs by 60–90 %, depending on traffic patterns and cache hit rates.
Q3: What are the best practices for combining caching and feedback?
Use semantic cache keys, refresh outdated data automatically, and blend human-in-the-loop review for sensitive queries.
Q4: How does caching impact sustainability in LLM apps?
By avoiding redundant compute calls, caching lowers both energy usage and cloud carbon footprint, enabling greener GenAI operations.
