MLOps & AI Infrastructure
The model is only 10% of the system. The rest is infrastructure. We build secure, automated MLOps Pipelines that transform experimental code into Production-Grade Systems ensuring reliability, observability, and governance at enterprise scale.
Stop "Throwing Models Over the Wall"
Reproducibility
Every model version can be traced back to the exact code and data used to train it. No more "it works on my machine."
Observability
We detect Data Drift and Concept Drift in real-time, alerting you exactly when a model's performance dips.
Governance
Full audit trails of who deployed what model and when. Crucial for compliance in FinTech and Healthcare.
Our MLOps Engineering Capabilities
End-to-End CI/CD for ML
Automated Deployment.
- Automated Unit & Integration Testing.
- Canary Deployments & Blue/Green Rollouts.
- Accuracy Gates” that block bad models from reaching Production.
Model Serving & Inference
Low-Latency APIs.
- Real-time REST/gRPC Endpoints (FastAPI, Triton).
- Serverless Batch Processing pipelines.
- Auto-scaling on Kubernetes (K8s HPA).
Observability & Drift Detection
Automated Monitoring.
- Data Drift: Detect when input data changes (e.g., demographics shift).
- Concept Drift: Detect when model logic becomes outdated.
- Real-time Alerting via Slack/PagerDuty.
Feature Stores
Consistent Data.
- Centralized Feature Registry (Feast/Databricks).
- Point-in-time correctness for training.
- Real-time feature serving for online inference.
Model Governance
Compliance & Registry.
- Model Versioning (v1.0 vs v1.1).
- Approval Workflows (Human sign-off).
- Artifact tracking (Weights, Biases, Docker Containers).
Infrastructure as Code (IaC)
Reproducible Environments.
- Terraform/CloudFormation modules.
- GPU Resource Optimization (Spot Instances).
- Multi-Cloud / Hybrid Deployments.
Enterprise Tooling & Platforms
Cloud Platforms

AWS SageMaker

Azure ML

Google Vertex AI

Databricks
Orchestration

Kubeflow

Airflow

Prefect

MLflow
Serving

NVIDIA Triton

TorchServe

BentoML

KServe
Infrastructure

Kubernetes (EKS/AKS)

Docker

Terraform
The "Continuous Training" Loop
A self-healing system that detects degradation and triggers retraining automatically.
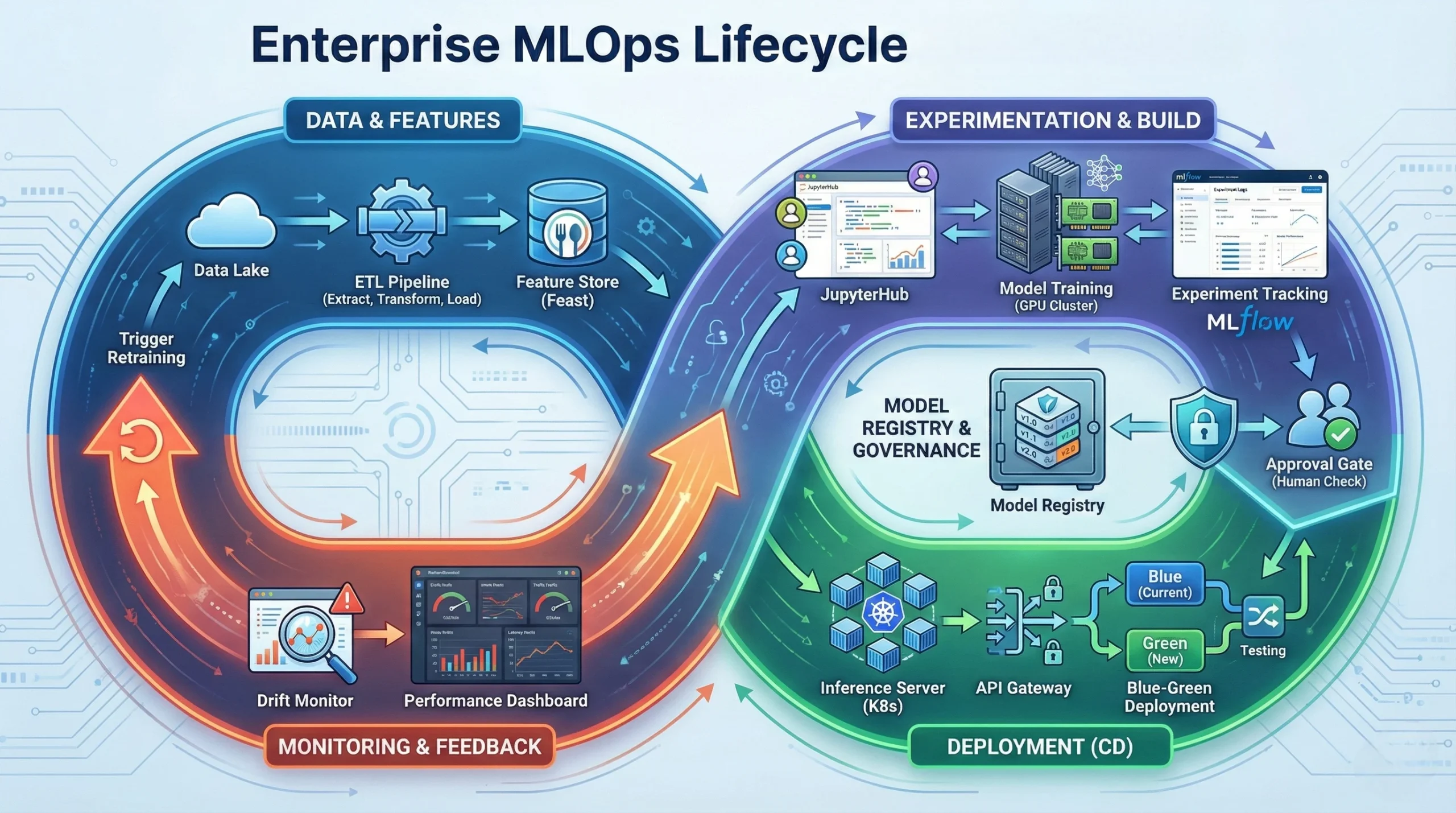
Operations in Production: Real Results
Real-Time Credit Scoring Pipeline
Built a low-latency inference engine serving predictions in <50ms, with automated retraining every week based on new transaction data.
Multi-Region Demand Forecasting
Scaled a forecasting model to 10,000+ SKUs using Ray on Kubernetes, reducing compute costs by 40% via Spot Instances.
Edge AI Deployment
Automated the deployment of optimized quantization models to 500+ edge devices in manufacturing plants via OTA updates.
Solutions Relying on MLOps
Infrastructure is the backbone of these high-scale applications.
Forecasting
Massive batch processing.
Recommendations
A/B testing frameworks.
Route Optimization
Daily retraining loops.
Infrastructure Questions
Do you support "Air-Gapped" or On-Premise deployments?
Yes. For defense and healthcare clients, we deploy full MLOps stacks on OpenShift or bare-metal Kubernetes, with no internet connectivity required.
How do you handle "Concept Drift"?
Can you modernize our existing monolithic model scripts?
Yes. A common engagement is “MLOps Modernization,” where we refactor monolithic Python scripts into modular, containerized pipelines (Docker/Kubeflow) for better scalability.