LLM & Generative AI Engineering
We don’t just wrap APIs. We engineer secure, domain specific AI systems. From Fine Tuning Llama 3 on your private data to building Reasoning Copilots that automate complex workflows we deliver GenAI that is compliant, observable, and hallucination-resistant.
Why You Need Custom Engineering, Not Just APIs
Data Sovereignty
Don't send PII to public models. We deploy Private LLMs within your VPC (AWS/Azure) or on-premise air-gapped servers.
Domain Accuracy
Generic models fail on jargon. We Fine-Tune models on your legal, medical, or financial data for >95% accuracy.
Cost Optimization
We optimize token usage and deploy Small Language Models (SLMs) to reduce inference costs by up to 60%.
Our GenAI Engineering Capabilities
Custom LLM Fine-Tuning
Turn a generic model into an expert.
- Supervised Fine-Tuning (SFT) on proprietary datasets.
- RLHF / DPO (Direct Preference Optimization) for alignment.
- Adaptation of Llama 3, Mistral, and Falcon.
Copilots & Intelligent Assistants
Move beyond simple chat.
- Internal Knowledge Copilots (HR/IT/Eng).
- Sales & CRM Assistants with function calling.
- Code Generation & Engineering Assistants.
RAG Knowledge Systems
Ground your AI in truth.
- High-performance Vector Retrieval (Pinecone/Qdrant).
- Hybrid Search (Keyword + Semantic).
- Citation & Source Tracking.
Model Optimization & Inference
High speed, lower bills.
- Quantization (4-bit/8-bit) for faster inference.
- Model Distillation (Teacher -> Student models).
- vLLM / TGI deployment for high throughput.
GenAI Security & Guardrails
Safety filters for input/output.
- PII Redaction & Masking.
- Jailbreak Prevention & Topic Guardrails.
- Toxicity & Bias Filtering (Nvidia NeMo).
Multimodal AI Solutions
AI that sees, hears, and speaks.
- Vision-Language Models (GPT-4V, LLaVA).
- Audio Intelligence (Whisper integration).
- Complex PDF/Chart Analysis.
Model Agnostic & Cloud Native
Open Models

Meta Llama 3

Mistral

Gemma
Closed Models

OpenAI GPT-4o

Anthropic Claude 3.5

Google Gemini 1.5
Serving & Ops

vLLM

Ollama

HuggingFace TGI

LangSmith
Infrastructure

AWS Bedrock

Azure AI Studio

NVIDIA NIM
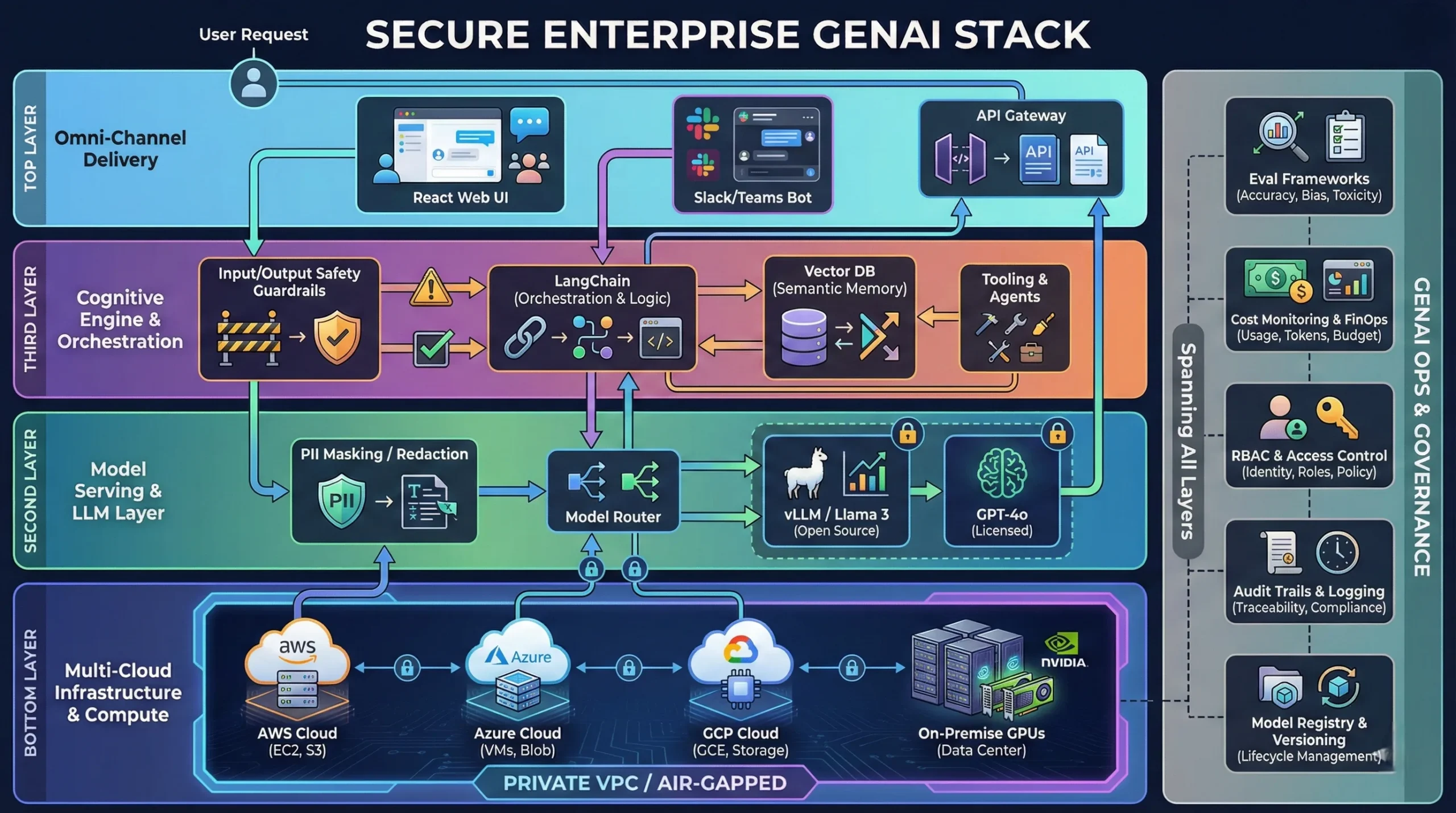
How We Architect Secure GenAI Systems
From the GPU layer to the User Interface, we control the entire stack.
GenAI in Production: Real Results
Custom Legal LLM for Contract Review
Fine-tuned Llama 3 on 50k legal contracts to automate risk flagging with 92% accuracy vs human lawyers.
Engineering Support Copilot
Built a RAG-based copilot ingesting 10 years of Jira tickets, reducing L1 resolution time by 65%.
Clinical Note Summarization
Deployed a private, HIPAA-compliant summarization engine processing 1M+ patient records securely.
Solutions Powered by Our GenAI Engine
Document Intelligence
Extract data from PDFs.
Enterprise Search
RAG-based search for SOPs.
Compliance Agents
Regulatory Q&A bots.
Common Engineering Questions
Do you use our data to train public models?
How much data do we need to fine-tune a model?
For Instruction Tuning (teaching a behavior), we can see results with as few as 500-1,000 high-quality examples. For Domain Adaptation (teaching knowledge), we need significantly more.
How do you handle "hallucinations"?
We use a RAG-First approach (grounding answers in retrieval), coupled with Self-Reflection Agents and deterministic guardrails (Nvidia NeMo) to block unsupported claims.
Can you deploy on-premise?
Yes. We specialize in deploying open-source models (Llama 3, Mistral) on your own hardware using containerized serving (Docker/Kubernetes).