Enterprise Knowledge Retrieval (RAG)
Stop guessing. Start knowing. We build secure Retrieval Augmented Generation systems that connect your LLMs to your private data (PDFs, SQL, SOPs) delivering answers that are accurate, citable, and grounded in your enterprise truth.
Why Public LLMs Fail in the Enterprise
Generic Data
Public models don't know your business. RAG bridges the gap by injecting your private contracts, logs, and manuals into the model's context.
Security Risk
Fine-tuning on sensitive data can be risky. RAG keeps your data in a secure Vector Database, never training the public model.
Verifiability
Hallucinations destroy trust. Our RAG systems provide Citations (Source Link + Page #) for every answer generated.
Advanced RAG Engineering Capabilities
Hybrid Search Architecture
Precision + Understanding.
- Combine Semantic Search (Vector embeddings) with Keyword Search (BM25).
- Capture specific product codes (Keywords) and broad concepts (Vectors).
Intelligent Document Processing (IDP)
Unstructured to Structured.
- Parse complex PDFs, tables, charts, and handwritten notes.
- Intelligent Chunking strategies (Parent-Child chunking) for context retention.
Re-Ranking & Optimization
The "Best Match" First.
- Implement Cross-Encoders (Re-rankers) to score search results.
- Filter out irrelevant noise before it reaches the LLM context window.
Vector Database Management
Scale to Billions.
- Architecture optimization for Pinecone, Weaviate, or Qdrant.
- Metadata filtering for RBAC (Role-Based Access Control) enforcement.
Citation & Grounding
Trust but Verify.
- Strict “Answer from Context Only” prompts.
- UI rendering of source PDFs highlighting the exact paragraph used.
Real-Time Indexing
Always Up-to-Date.
The Retrieval Stack
Vector DBs

Pinecone

Weaviate

Qdrant

Milvus

Azure Search
Embeddings

OpenAI

Cohere

HuggingFace
Frameworks

LangChain
LlamaIndex

Haystack
Parsing

Unstructured.io

Amazon Textract

Azure Form Recognizer
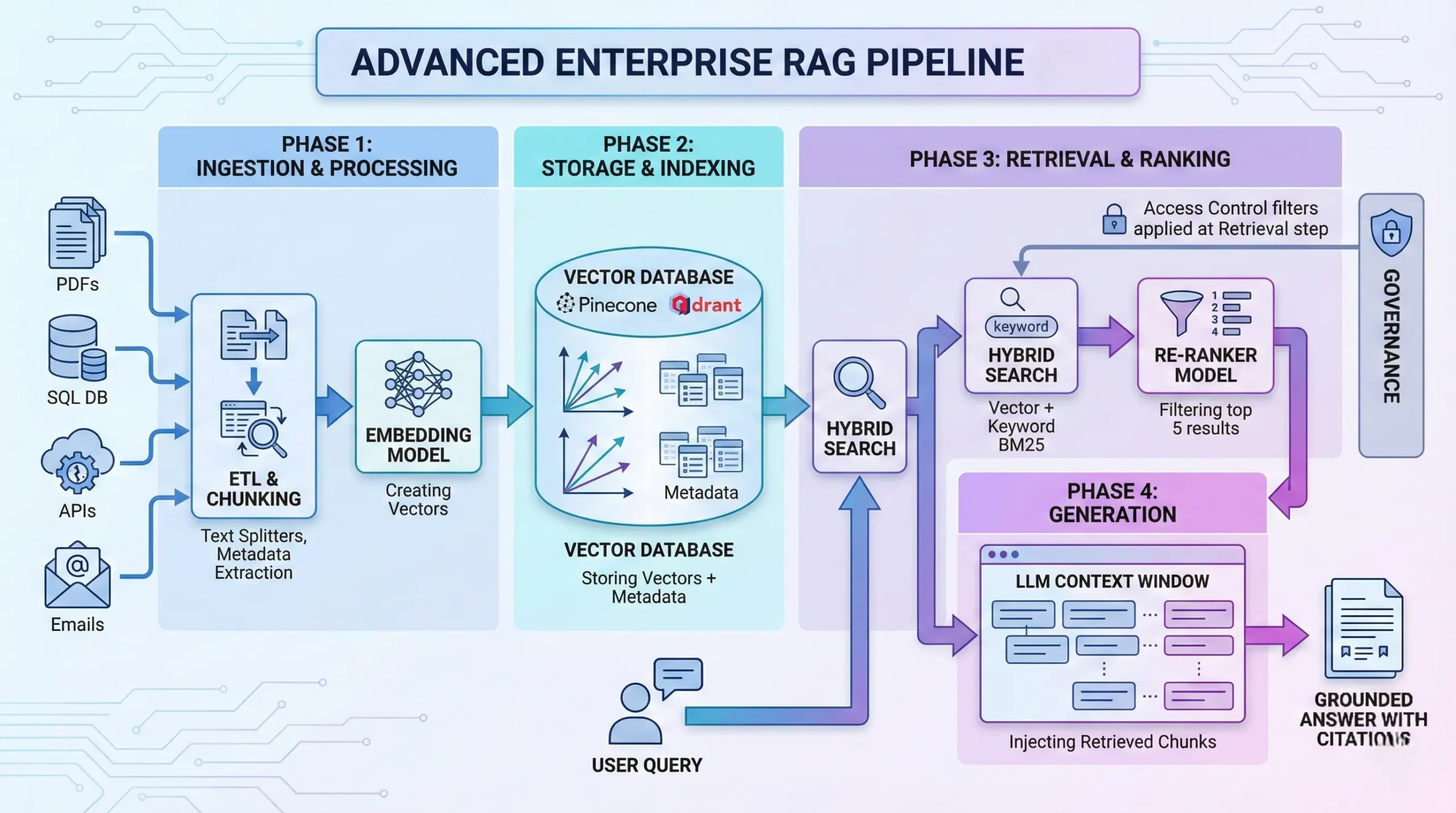
The "Advanced RAG" Pipeline
How we transform raw chaos into structured intelligence.
RAG in Production: Real Results
Technical Field Assistant
Ingested 50,000 pages of machinery manuals. Reduced field engineer diagnosis time by 40% via instant SOP retrieval.
Contract Intelligence Engine
Built a RAG system for a law firm to query 10 years of case files, identifying precedents with citation accuracy of 99%.
Compliance Policy Copilot
Enabled bank staff to query complex regulatory PDFs. Reduced compliance oversight hours by 30%.
Solutions Powered by RAG
Enterprise Search
Unified search across Jira & Drive.
Document Intelligence
Extract data from invoices.
Compliance Agents
Chat with regulatory docs.
Support Agents
Look up KB articles instantly.
RAG Engineering Questions
How do you handle tables and charts in PDFs?
Standard text extraction fails here. We use Multi-Modal Parsing (using Vision models) to convert tables into markdown or structured JSON before embedding them, preserving the data context.
How secure is the Vector Database?
We use enterprise-tier Vector DBs (Pinecone Enterprise or Azure AI Search) that support Single Tenant deployment, encryption at rest, and PrivateLink connections.
How do you prevent the AI from answering questions it shouldn't?
We implement RBAC (Role-Based Access Control) filters at the retrieval level. If a user doesn’t have permission to view a document, the RAG system won’t even retrieve it, so the LLM never sees it.
Delivering AI Solutions Across the Globe
- India
- USA
- UAE
- Europe
- Singapore
- Australia
Turn Your Documents into Intelligence
Stop searching. Start finding.